Java 中有多种常量池,常量池可以实现数据共享,节省内存开销,避免频繁创建对象与销毁对象等诸多好处。
常量池分类
一般,Java 中的常量池被分为以下几类:
- class 字节码常量池:保存字面量(就是一些字符串和被final修饰的变量)和符号引用(类名、方法名、变量名)
- 运行时常量池:在类被加载到内存之后,将Class中常量池转变为运行时常量池,存在于方法区
- String 字符串常量池:保存字符串的常量池,存在于堆区
字节码常量池(常量池表 Constant Pool Table)
class 常量池包含运行特定类的代码所需的常量,它是一种类似于符号表的数据结构。其内容由编译器生成的符号引用组成。这些引用是代码中引用的变量、方法、接口和类的名称。JVM使用它们将代码与它所依赖的其他类链接起来。
使用一个简单的 Java 类来了解常量池的结构:
package com.mapull;
/**
* Hello world!
*
*/
public class MapullApplication
{
public static void main( String[] args ) {
System.out.println( "Welcome to mapull.com" );
}
}
将上述代码编译后,执行命令:
javap -v MapullApplication.class
执行完上述命令后,可以在结果中看到如下内容:
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // Welcome to mapull.com
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // com/mapull/MapullApplication
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 MapullApplication.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 Welcome to mapull.com
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 com/mapull/MapullApplication
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
输出结果和表十分类似:
- 每行一条记录,分两列
- 第一列 #n 表示行号,从1开始, = 后面为类型
- 第二列可以为内容,如 #14,可以为引用,如 #26,如果为引用,会在 // 后标注实际内容
- #3 和 #18 都表示字符串内容,但是它们的类型不同
上面的常量池中出现了如下的类型:
- Fieldref、Methodref:字段符号引用、方法符号引用,一对以点分隔的值,前面表示 Class,后面表示 NameAndType
- String:一个 16 位字符串常量,指向池中包含实际字节的另一条数据
- Class:包含完全限定的类名
- Utf8:字节流
- NameAndType:一对冒号分隔的值,前面表示名称,后面表示类型
此外还有一些没有出现的类型:
- Integer:整数字面量,32 位
- Float:浮点数字面量,32 位
- Double:双精度浮点数字面量,64 位
- Long:长整形字面量,64 位
需要注意的是,如果在代码中定义为 boolean、short和byte,都会被表示成 Integer。
运行时常量池(Runtime Constant Pool)
运行时常量池是方法区的一部分。运行时常量池相对于CLass文件常量池的另一个重要特征是具有动态性,Java语言并不要求常量必定只有编译期才能产生,也就是并不是预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的 intern() 方法。
字符串常量池(String Table)
在 HotSpot VM 里,字符串常量池是通过 StringTable 类来实现的,它是一个hash表,即通过计算String对象的hashcode,决定要将其存储在表中的哪个位置,StringTable 在JVM中只有一个实例,被所有的类共享。
StringTable 默认大小为1009,可以通过下面的参数来修改:
-XX:StringTableSize=2048
在JDK6.0及之前版本中,String Pool里放的都是字符串常量,这些常量都放在Perm Gen区(也就是方法区)中;
在JDK7.0中,String Pool里放的实际上是字符串对象的引用,对象的实体存储被转移到堆内存中,这样做是因为方法区存储空间有限,一旦常量池过大会导致OOM。
在JAVA8中,永久代概念被去除,采用元空间 Metaspace 来存储类的元数据。
package com.mapull;
public class MapullApplication
{
public static void main( String[] args ) {
String a = "Welcome";
String b = "Welcome";
String c = new String("Welcome");
String d = new String("Welcome");
String e = "Wel" + "come";
}
}
通过 javap 命令可以看到如下内容(仅节选部分):
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = String #16 // Welcome
#3 = Class #17 // java/lang/String
#4 = Methodref #3.#18 // java/lang/String."<init>":(Ljava/lang/String;)V
#16 = Utf8 Welcome
#17 = Utf8 java/lang/String
Code:
stack=3, locals=6, args_size=1
0: ldc #2 // String Welcome
2: astore_1
3: ldc #2 // String Welcome
5: astore_2
6: new #3 // class java/lang/String
9: dup
10: ldc #2 // String Welcome
12: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
15: astore_3
16: new #3 // class java/lang/String
19: dup
20: ldc #2 // String Welcome
22: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
25: astore 4
27: ldc #2 // String Welcome
29: astore 5
31: return
LineNumberTable:
line 6: 0
line 7: 3
line 8: 6
line 9: 16
line 10: 27
line 11: 31
为了更好地分析数据,我将上面的内容转换成表格:
| 行号 | 代码 | LineNumberTable | 字节码 Code | 字节码 Constant pool |
|---|---|---|---|---|
| 6 | String a = “Welcome”; | line 6: 0 | 0: ldc #2 | #2 = String #16 // Welcome |
| 7 | String b = “Welcome”; | line 7: 3 | 3: ldc #2 | #2 = String #16 // Welcome |
| 8 | String c = new String(“Welcome”); | line 8: 6 | 6: new #3 | #3 = Class #17 // java/lang/String |
| 9 | String d = new String(“Welcome”); | line 9: 16 | 16: new #3 | #3 = Class #17 // java/lang/String |
| 10 | String e = “Wel” + “come”; | line 10: 27 | 27: ldc #2 | #2 = String #16 // Welcome |
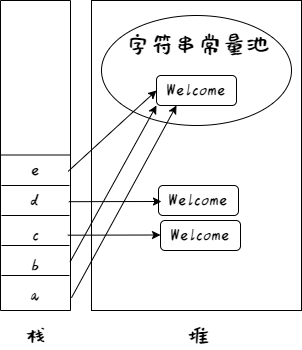
也就是说,a、b的值在编译阶段就能确定下来,为字符串常量 Welcome。c、d无法直接得到字符串的值,它们的内容在运行阶段确定。比较意外的是,从 e 的值可以看出,字符串操作符 + 在编译阶段即可确定内容。
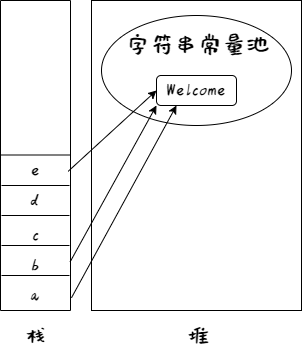
编译过后,a、b、e 指向的相同的字符串常量池区域,因此: a b e
对于 c、d来说,它们通过 new 关键字创建,其生成的对象不在常量池中。