HashMap 是 Java 集合框架中非常重要的一个实现,它有非常多值得借鉴的实现思路。面试中,也被经常问到。
下面将根据一系列的问题,来逐步深入了解 HashMap。
HashMap 底层结构
了解底层结构,将有助于理解更多复杂的设计思路。
HashMap 的底层结构是什么?
数组 + (链表 | 红黑树)
底层结构,HashMap 1.7和1.8实现有什么不同?
1.7 为 数组 + 链表。1.8 为 数据 + 链表/红黑树。
HashMap 为什么引入红黑树?
链表的查询复杂度为 O(n),而红黑树的查询复杂度为 O(logn)。
引入红黑树能明显提高查询性能。
HashMap 为什么是红黑树,不是其他树?
除了红黑树,还有 AVL 树,B 树等。B树不平衡,甚至可能本身就退化成链表形式,起不到性能提升效果。AVL 树有更好的查询效果,通常查询性能优于红黑树,但这是牺牲插入和删除元素性能为代价的,维护 AVL 需要更多的旋转操作使其平衡。
红黑树更加通用,实现起来相对友好一些,旋转和变色次数少,相对更适合 HashMap。
为什么不是直接采用红黑树?
- 维护(添加、删除元素)红黑树平衡有性能消耗;
- 链表长度较短时,红黑树的查询性能与链表相差不大;
- 链表比红黑树占用的内存少,树比链表维护更多的数据;
树化的阈值是多少?为什么选择这个数?
树化阈值为 8 ,选择这个数也是经过数学论证的。在使用 HashMap 的默认参数情况下,长度为8的链表出现概率大约是 0.00000006,千万数据规模情况下,长度超过 8 的数量小于等于 1.
一般认为,随机的 hash 值产生情况满足泊松分布:
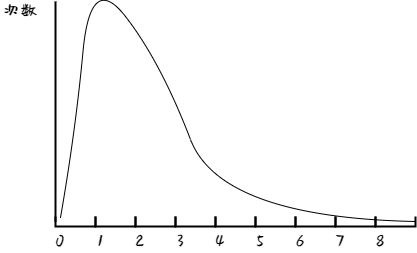
要想正常的业务场景产生红黑树非常难,红黑树的出现主要来避免 DoS 攻击,攻击者可能制造大量的相同 hash 值数据,导致系统性能急剧下降。
何时会树化?
树化一定要同时满足两个条件:
- 链表长度超过 8
- 数组长度超过 64
两个条件必须同时满足,在数组长度(桶数量)小于 64 时,就算链表长度为10(超过8)也还是链表,不会变成树。
何时退化为链表?
退化为链表在两种情景发生:
- 添加元素:扩容时,如果发生拆分树,且树的元素个数 <= 6 就会退化成链表
- 删除元素:移除树节点前,当 root 、root.left、root.right、root.left.left 有一个为 null,就会退化成链表
扩容时为啥元素 <=6 才会退化成链表,而不是 <= 8 退化?
这里存在一个中间缓冲值 7 ,防止添加元素时频繁发生树化和退化。
红黑树中最少有几个元素,发生在什么时候?
我们会想当然觉得红黑树中最少有 8 个元素,因为树化要求链表长度超过 8.
但是别忘了,添加元素时,可能存在扩容的情况,这时结合上面链表退化条件,你很可能得出结论:红黑树中最好的元素为 6 个。
就在你沾沾自喜中,这个题打错了,因为退化还有一种情况。
假设 HashMap 中存在如下的红黑树:
- 有9个元素的红黑树
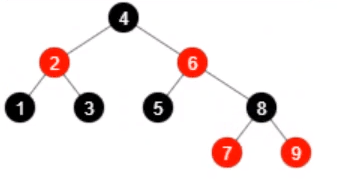
- 移除元素 7,还剩8个元素
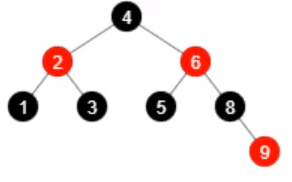
- 移除元素 9,还剩7个元素
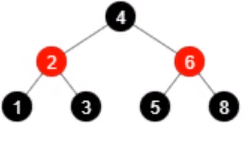
- 移除元素 8,节点变色,还剩6个元素
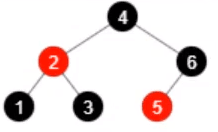
- 移除元素 6,还剩 5 个元素
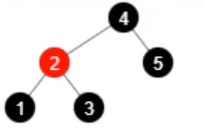
- 移除元素 5,还剩 4 个元素
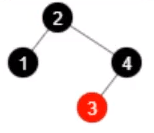
- 移除元素 3,还剩 3 个元素
移除元素前,root != null 且 root.left != null 且 root.right != null ,但是 root.left.left 为 null,移除元素后退化为链表。

因此这道题的正确答案为:红黑树中最少有 4 个元素,发生在移除元素时。
索引如何计算?
int index = (n - 1) & hash;
先调用 key 的 hashCode() 方法,再调用 HashMap 中的 hash() 方法,二次哈希的结果 hash & (capacity -1) 得到索引(桶下标)。
hash & (capacity -1) 实际上是 hash % capacity。
capacity 一般称之为 桶数量,实际上就是数组的长度。要想让元素随机分布到每个桶中,比较合理的方式就是对 桶数量 取余运算,余数就是桶下标。
但是为什么代码中为 hash & (capacity -1) ,这也涉及一个数学规律:对于一个 2 的 n 次幂整数,取余运算和按位与运算结果相同。
35 % 16 = 35 & (16 -1)
对于计算,与运算 & 要比 取余元素 % 快很多。
二次哈希的作用?
下面是二次哈希的代码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
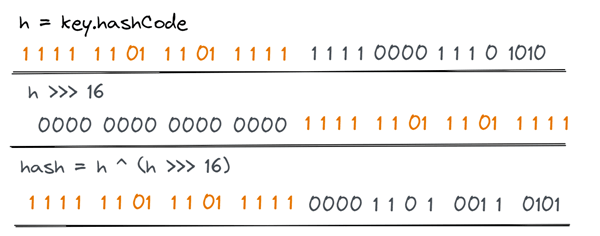
二次哈希让原始哈希值的高 16 位与低 16 位进行融合,增加哈希码的随机性。而更加随机的哈希值可以使得桶中元素相对平均,防止某些桶中出现超长链表甚至树化,而其他桶都是空的。
关于二次哈希算法,在JDK1.7中和 1.8 中并不相同,它并不是一个固定的算法:一个好的 hash 算法要足够快,且结果足够分散。
数组容量为什么是 2 的 n 次幂?
在计算索引时,可以利用数学规律:2 的 n 次幂可以使位运算 & 代替取余运算 %.
扩容时,(e.hash & oldCap) 0 的元素留在原来位置,否则新的位置 = 原始位置 + oldCap
选择 2 的 n 次幂可以使得很多计算得以优化,通过各种细节来提升 HashMap 的性能。
这个容量规则不是一个固定的结论,在 JDK 中,还有一个和 HashMap 类似的实现 Hashtable,它的容量就不是上面的规则,它初始扩容后为 11 ,之后为 23 ,其规律为上次容量翻倍 + 1
HashMap 添加元素 put() 的流程
- HashMap 是懒惰的,首次添加元素时才创建数组
- 计算索引,得到桶下标
- 如果桶中无元素,创建一个Node 占位
- 如果桶中有元素,说明 Hash 冲突了
- 如果为链表,则添加元素到链表尾部,若链表长度超过树化阈值 8 ,进行树化
- 如果是红黑树,则添加元素到红黑树中
- 检查容量是否超过设定值(cap * factor),若超过进行扩容(扩容是最后一个操作)
- 返回添加的元素
HashMap 负载因子有什么用,为啥选择 0.75 ?
在空间占用与查询效率之间取得一个较好的平衡。
- 较大的负载因子,空间节省,但是链表可能比较长,影响性能
- 较小的负载因子,冲突降低,扩容更为频繁,空间占用多
HashMap 线程安全吗?存在什么问题?
HashMap 在 JDK1.7 中添加元素时,哈希冲突后采用头插入添加元素到链表中,并发时存在死链问题(链表中有环)。在 JDK1.8 中采用尾插发解决了该问题,但是并发时可能出现数据丢失现象。
HashMap 不是线程安全的,在多线程情况下存在数据丢失问题。
HashMap key 有啥要求?
- key 可以有一个 null 值
- key 的对象需要实现 hashCode() 与 equals 方法
- key 需要是不可变对象(被final修饰)